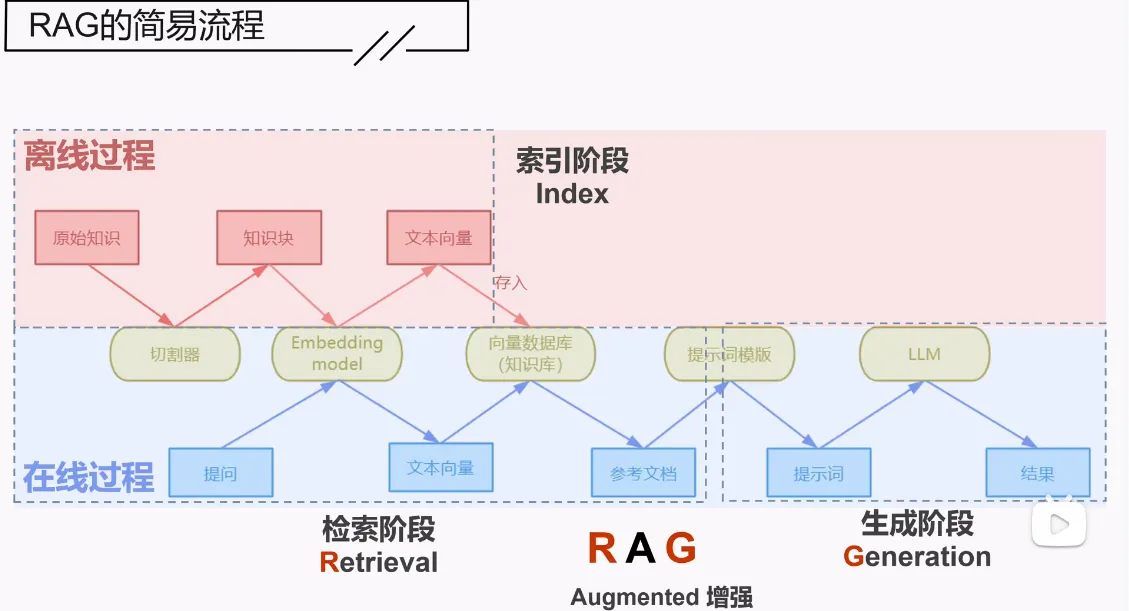
三个核心点:索引,检索,生成(大模型要做的)

索引
1.切割文档
1.切割文档的核心是要保证语义的连贯性,

2.切割文档的方法
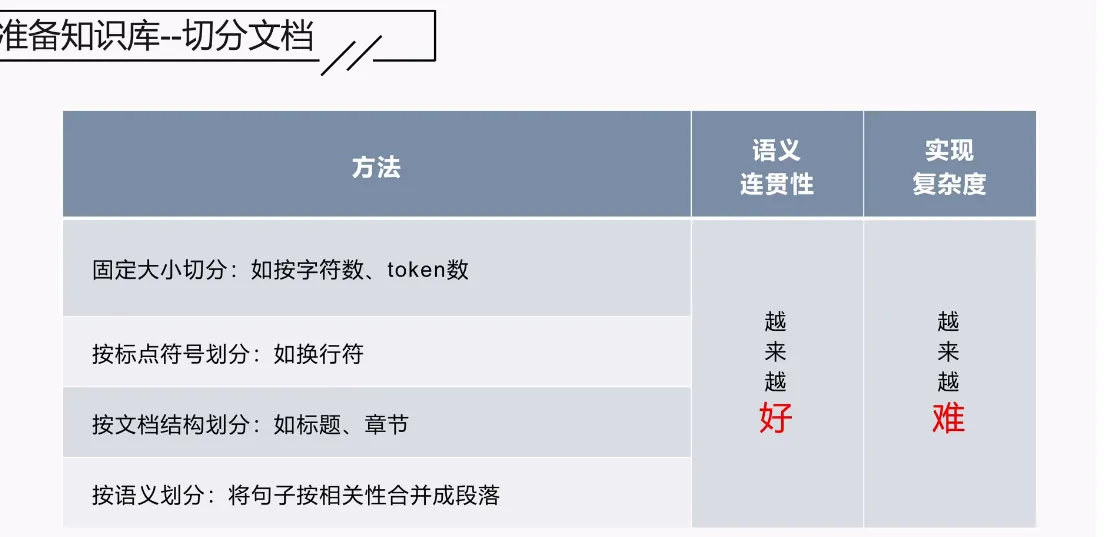
语义划分是通过滑动窗口加固定字符长度来实现的,所以会有重复的地方,这样也是保证上下文的语义。
2.文字转文本向量
1.怎么转化
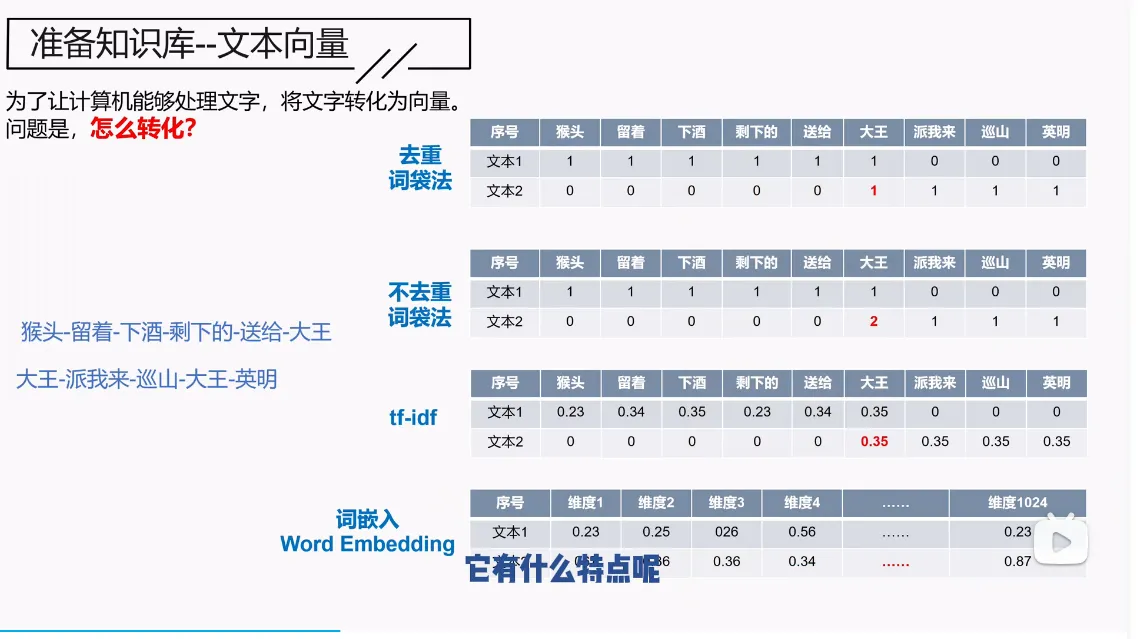
词嵌入的方法复杂,但是他的语义相关性可以捕捉的很好,可以捕捉到同义词比如:“高兴”与“快乐”,“北京”之于中国=“巴黎”之于法国,他可以判断你的语句意思,对应出你的北京在这段话的意思是北京,所以如果你后面是填空的话,他可以生成“巴黎”
2.向量存储

检索
根据文本向量到参考文档
1.基于文本相似度检索
这种的可能会慢一些,但是他会推测语义,得到的效果会更好一些,比如说空中的“铁鸟”为什么不会掉下来,他会推测出你说的其实是飞机,然后搜索飞机相关的东西,但关键字索引不会。

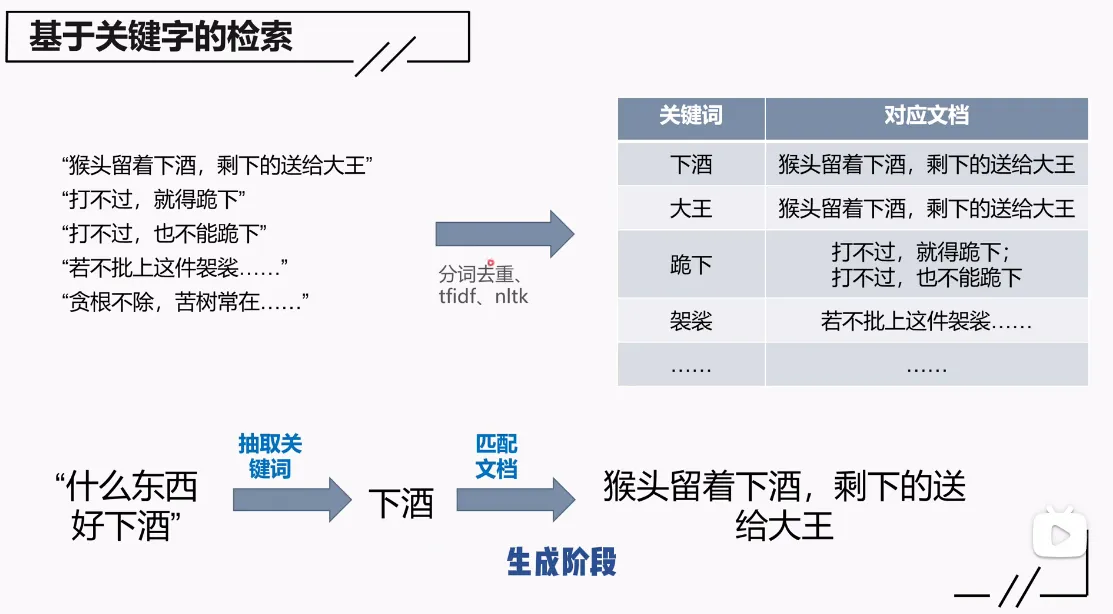
2.基于关键字的检索
像倒排索引,关键词会对应文档,但是相应的,他不是根据语义,只是根据关键词,所以适用于准确,提问比较详细的阶段,比如我想要中国法律的第几条法律条文
优化方案
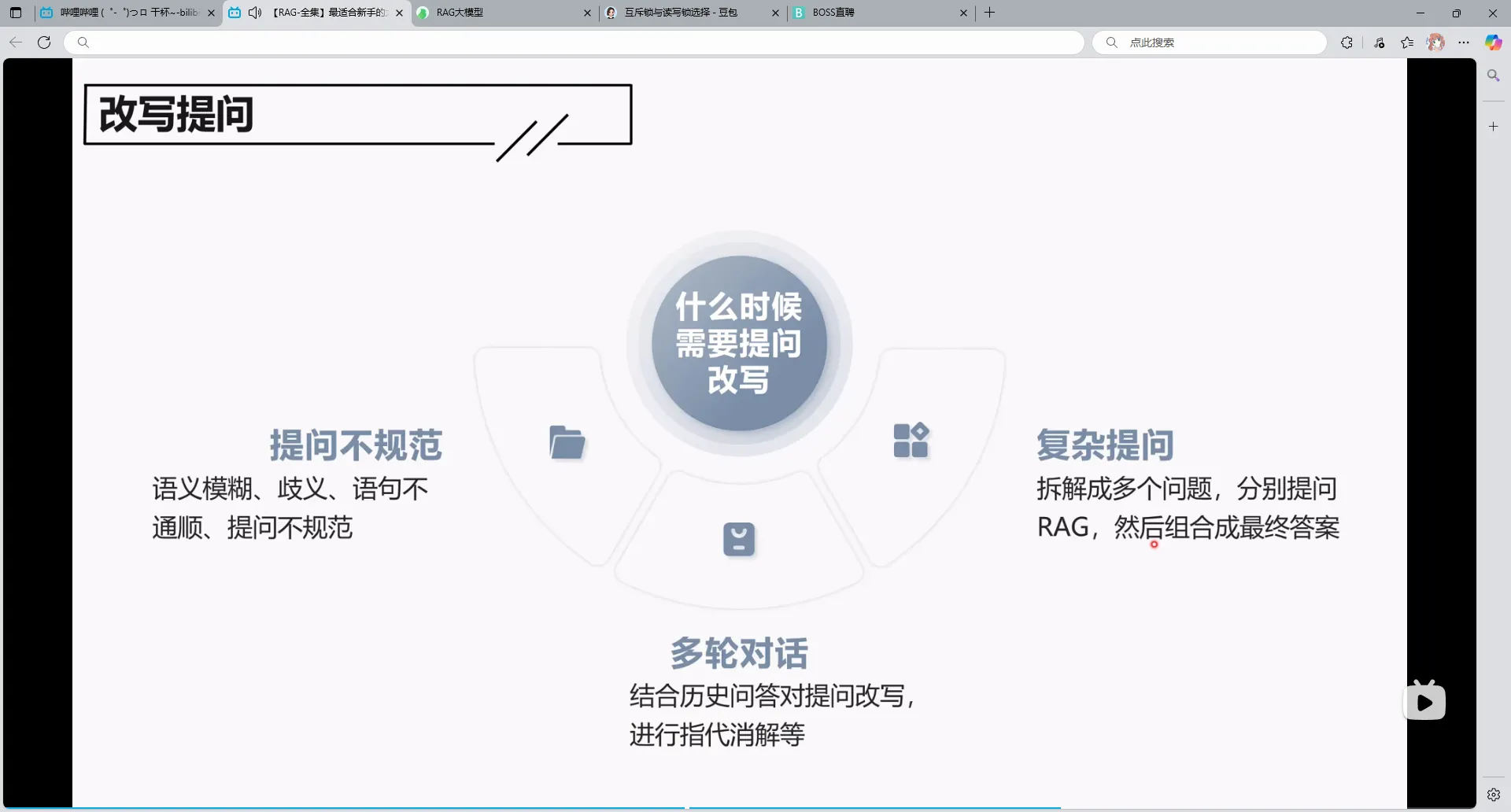
1.改写提问
用户的提问可能是模糊的,而且有可能是多轮对话,比如说:三国吕布多高,第二轮:他的武力多强,这个他就要改写成吕布
2.检索优化
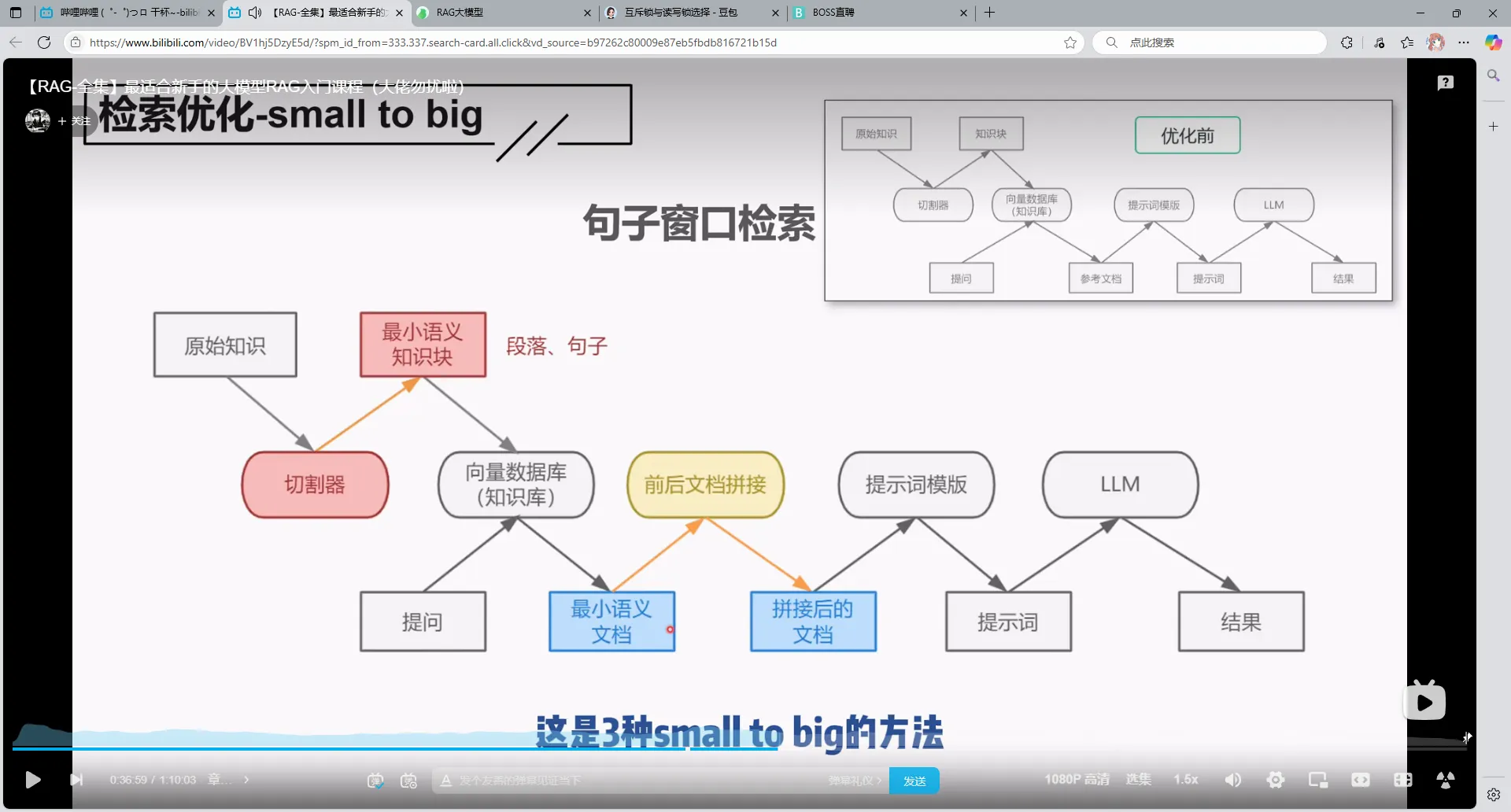
1.small to big
核心思想是存储的时候存储浓缩小块,然后检索的时候找到对应小块的完整知识库,所以是从小到大
2.多路召回
就是采取了文本相似度检索与关键字检索的最终结果,所以这种是很受欢迎的

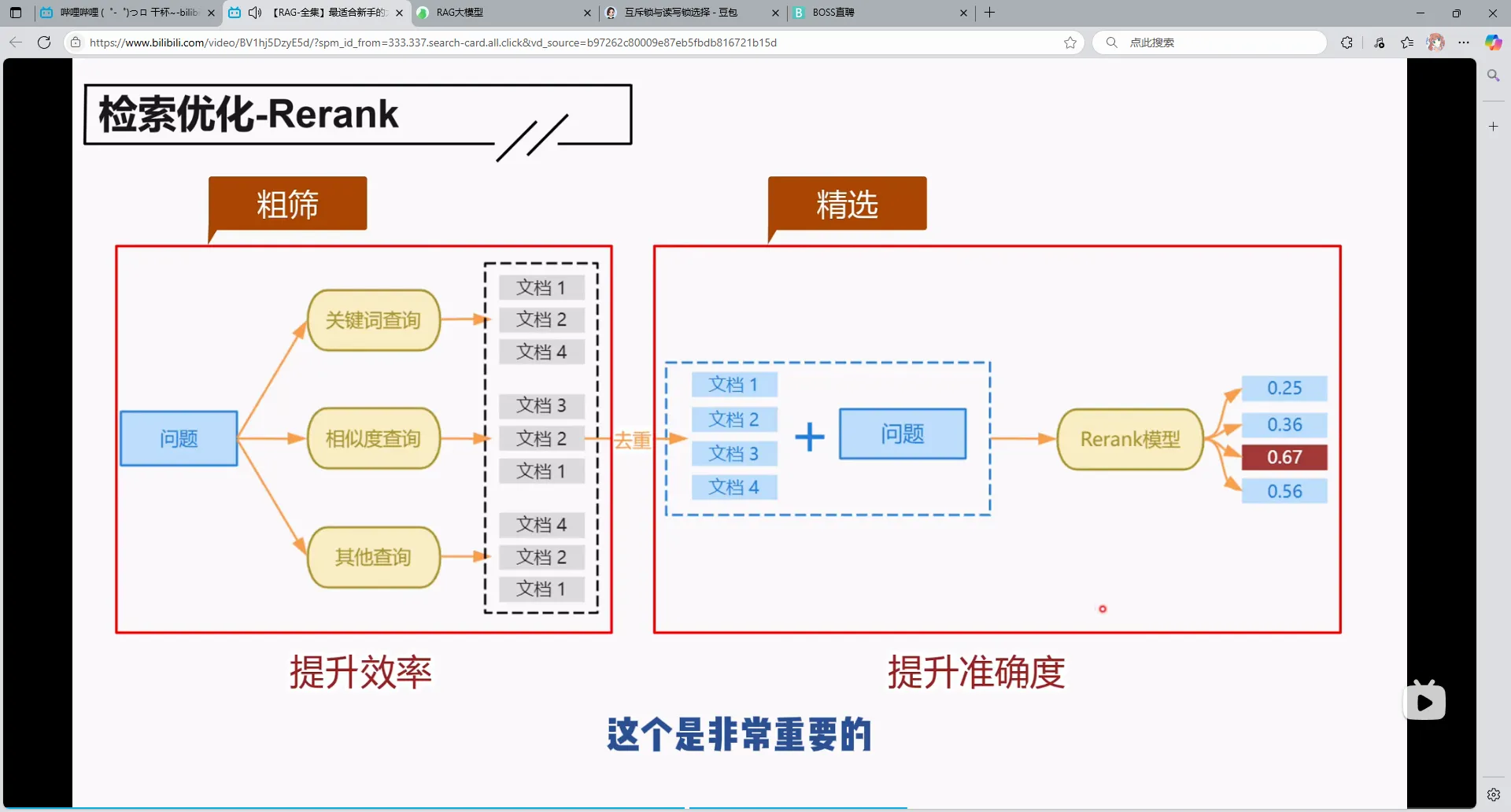
3.Rerank
先进行粗筛,然后用Rerank模型进行精选,不直接用Rerank是因为这个模型比较消耗资源的,所以要进行初次筛选。
3.生成优化
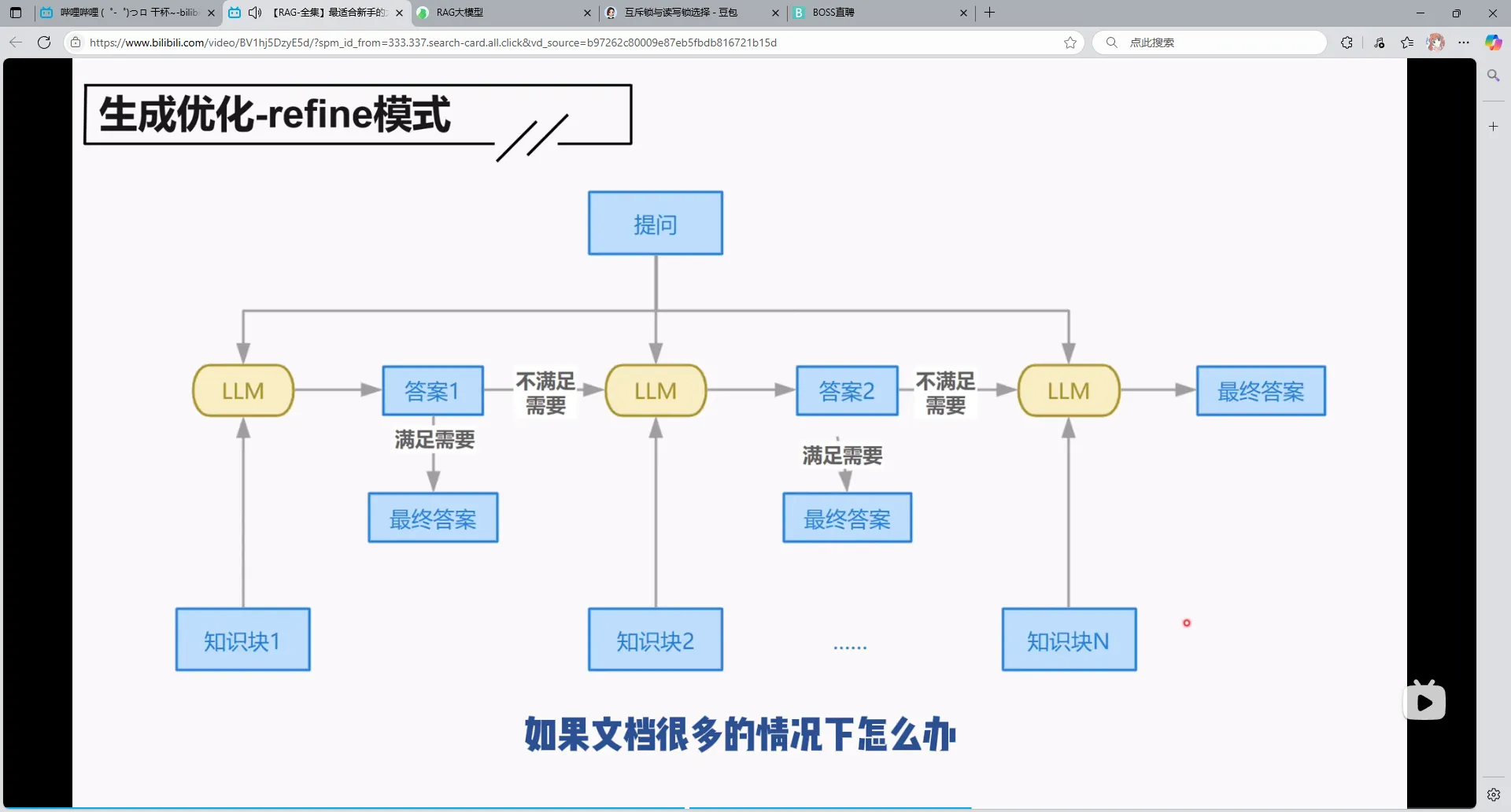
1.refine模式
相当于每个文档都用到了,但是相应的最坏情况下,如果你一直不满意直到最后的文档的话,那么就要一直调用大模型不断生成,这是比较消耗资源的。
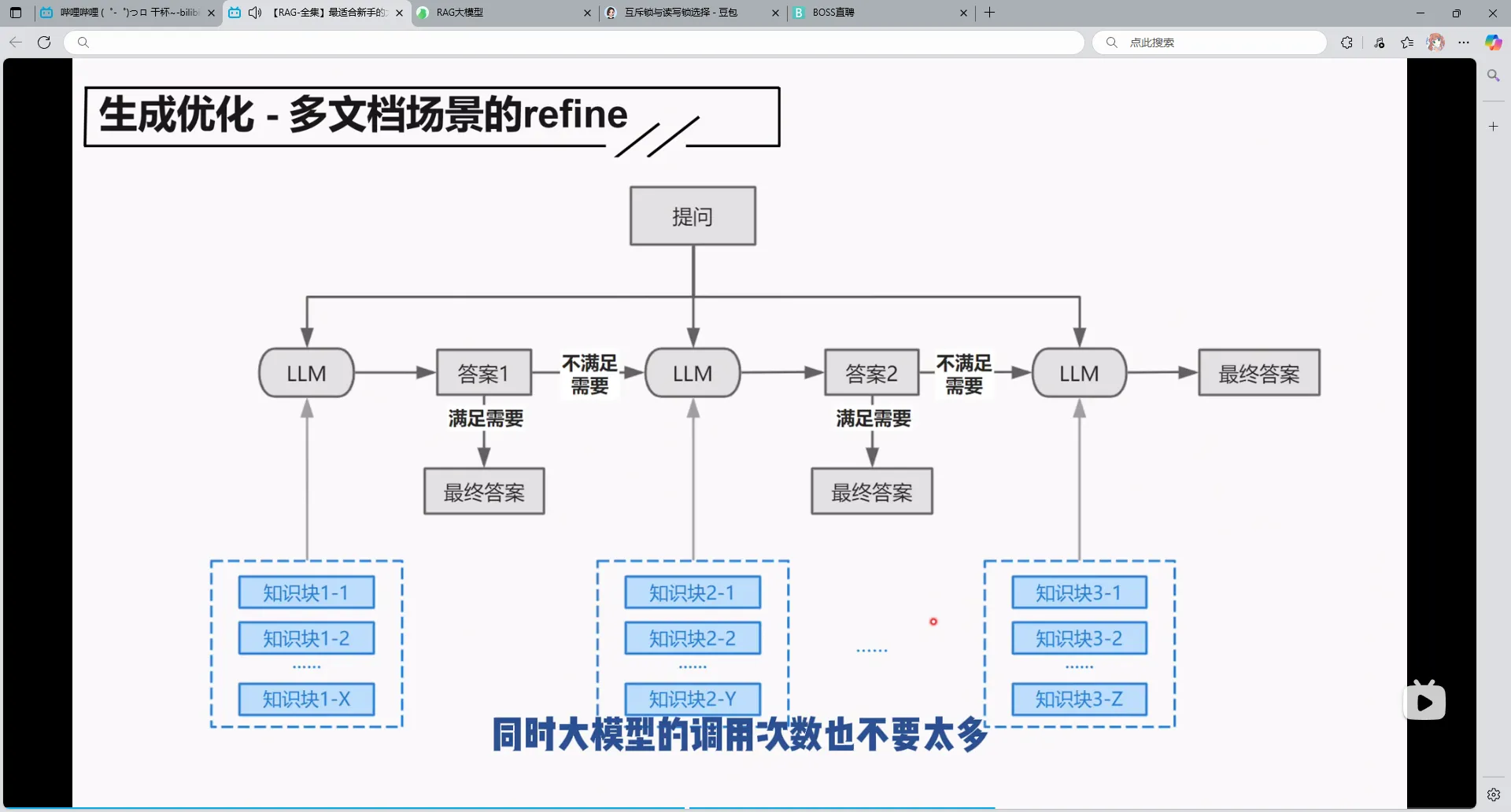
2.多文档场景的refine
其实跟refine没啥区别,就是一次性返回更多了,9个文档我3个3个返回,9次就变成了3次
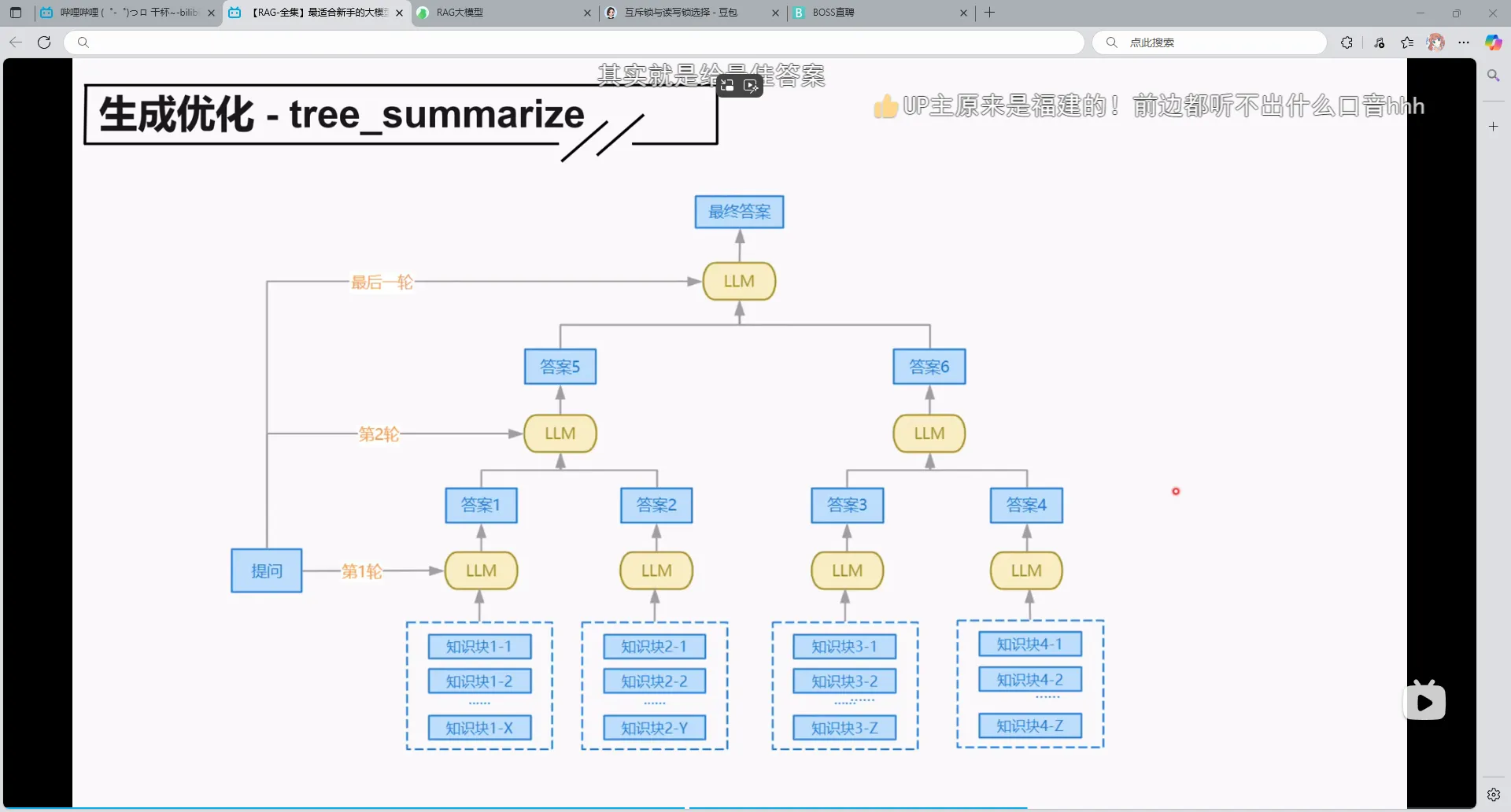
3.tree_summarize
把得到的答案不断优化,然后再生成,重复然后得到最终答案
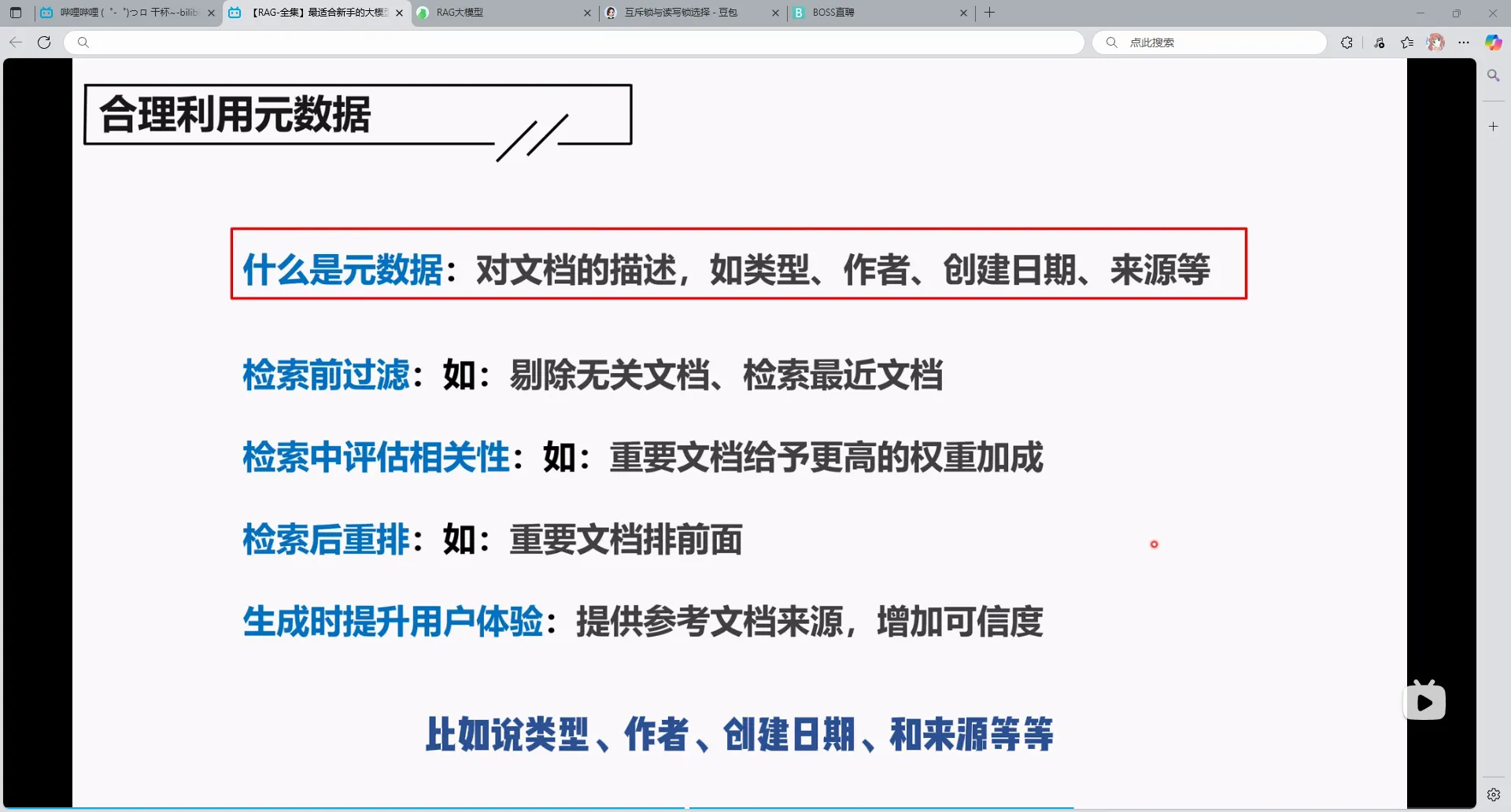
4.合理运用元数据
可以适当过滤,更改权重什么的
RAG的评估
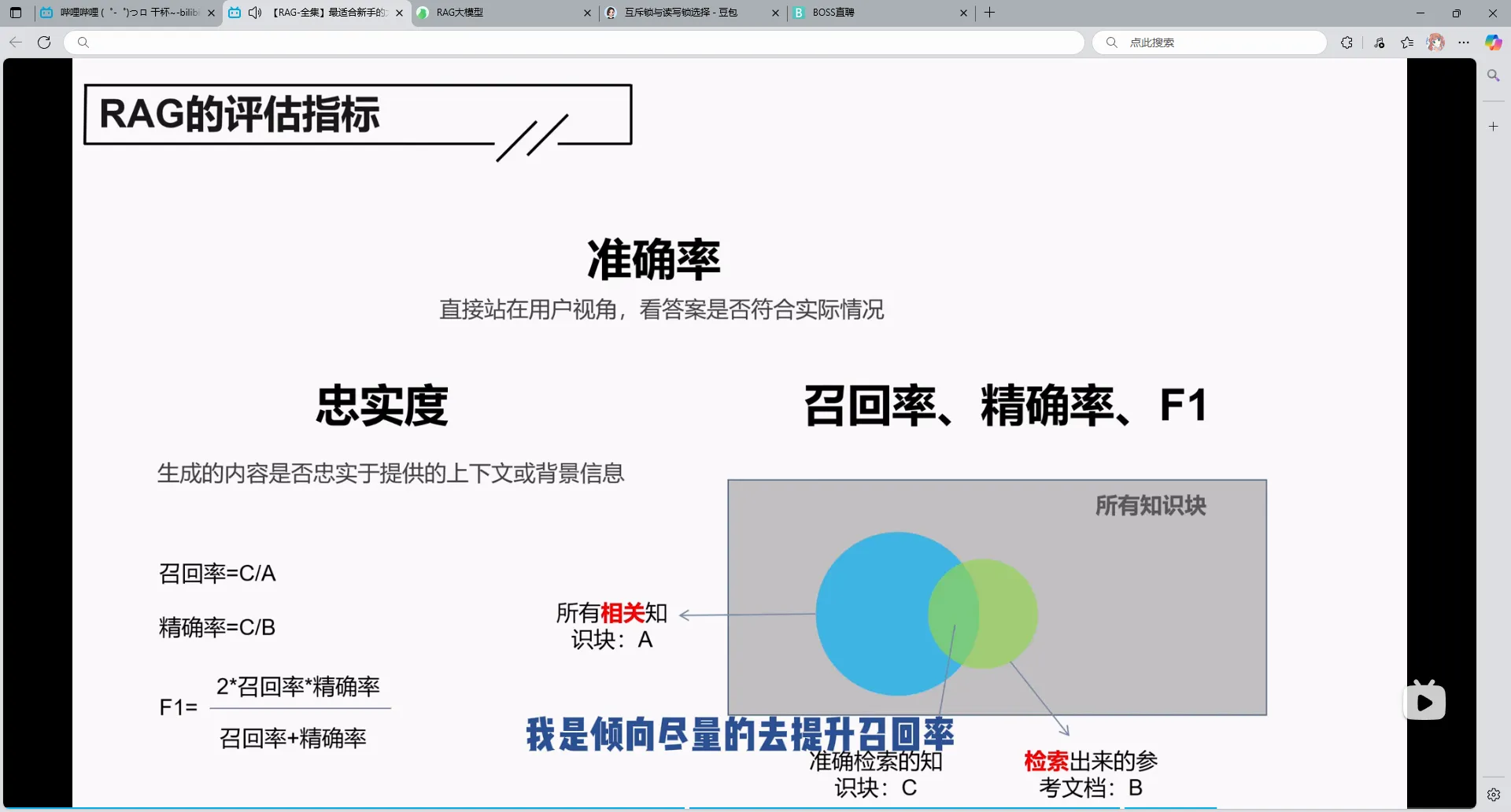
1.RAG的评估指标
忠实度指的是生成阶段的大模型有没有按照我的索引去检索,是否依照我的上下文来回答
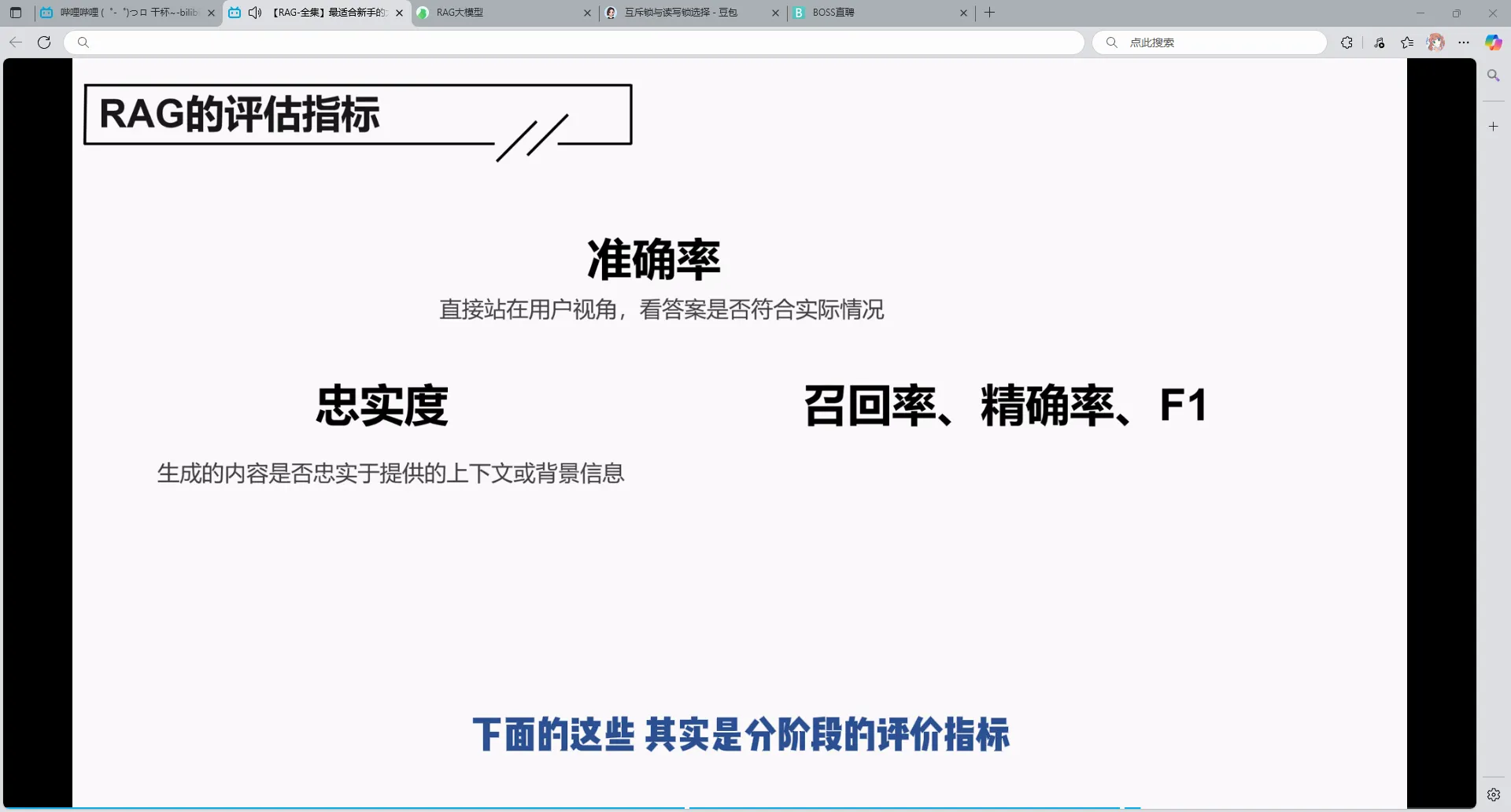
召回率与精确率是你生我降的关系,我感觉应该更重视召回率,因为大模型没有就是生成不了,但是如果你给多了,或者有错误,他可能会排除
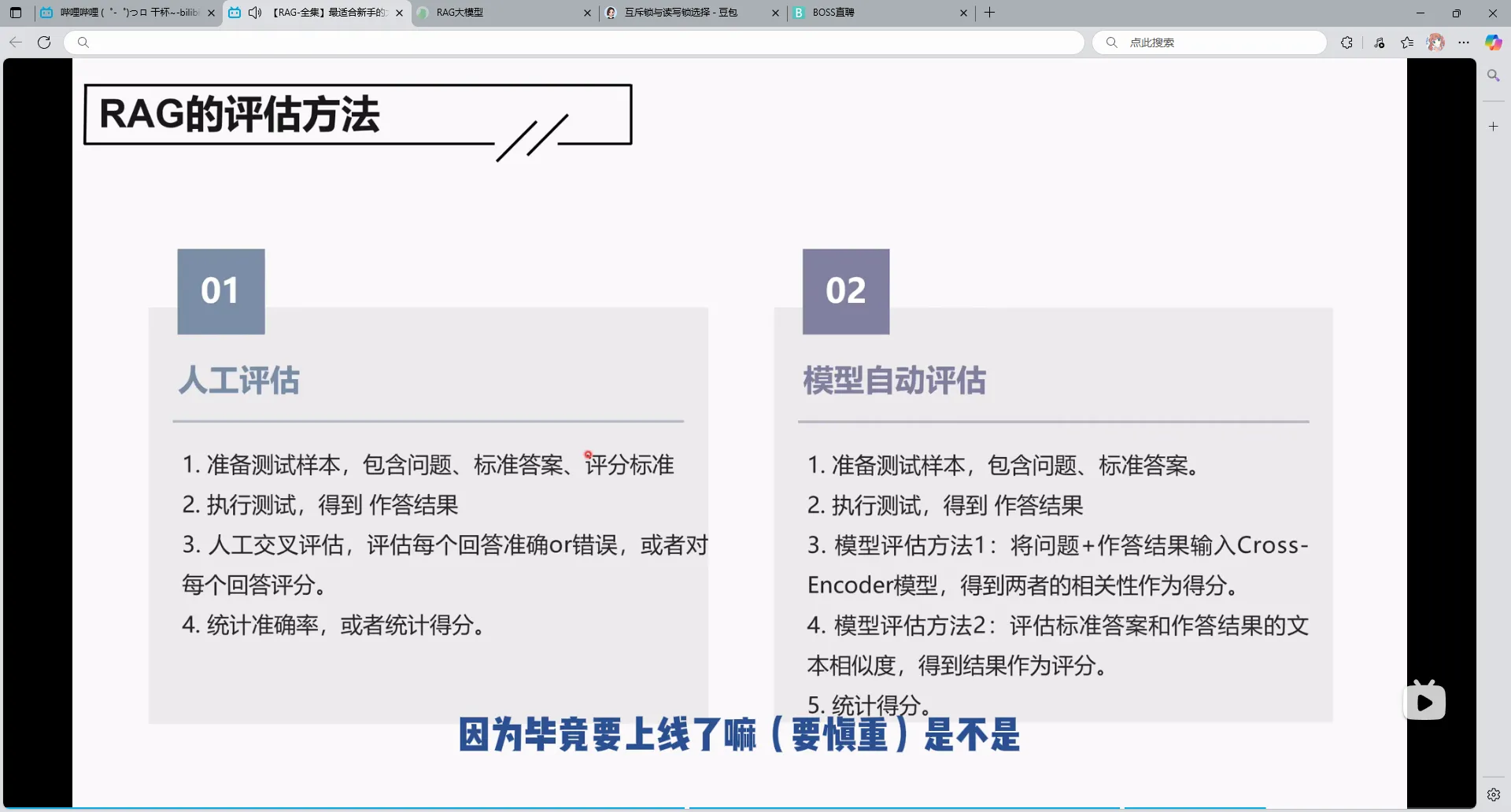
2.RAG的评估方法
评论