1.traceid的作用
1.traceid是骨架
traceid只关心服务调用,不关心业务问题,只要服务是通的,就算返回错误码什么的,他也不会报错,只有服务断了,他才会反馈。我们通过traceid主要是可以看到整个真实的链路,知道它调用了什么,以及调用关系。所以我们真正要看业务报错或者error什么的,要通过日志来看,当然,这个traceid分析可以是第一步,让我们看看服务有没有问题,骨架没有问题,我们就可以看血肉(日志),真正的业务了。
2.另外还有一个作用就是服务优化,他可以细分出我们每个环节的耗时,我们可以针对性的进行优化
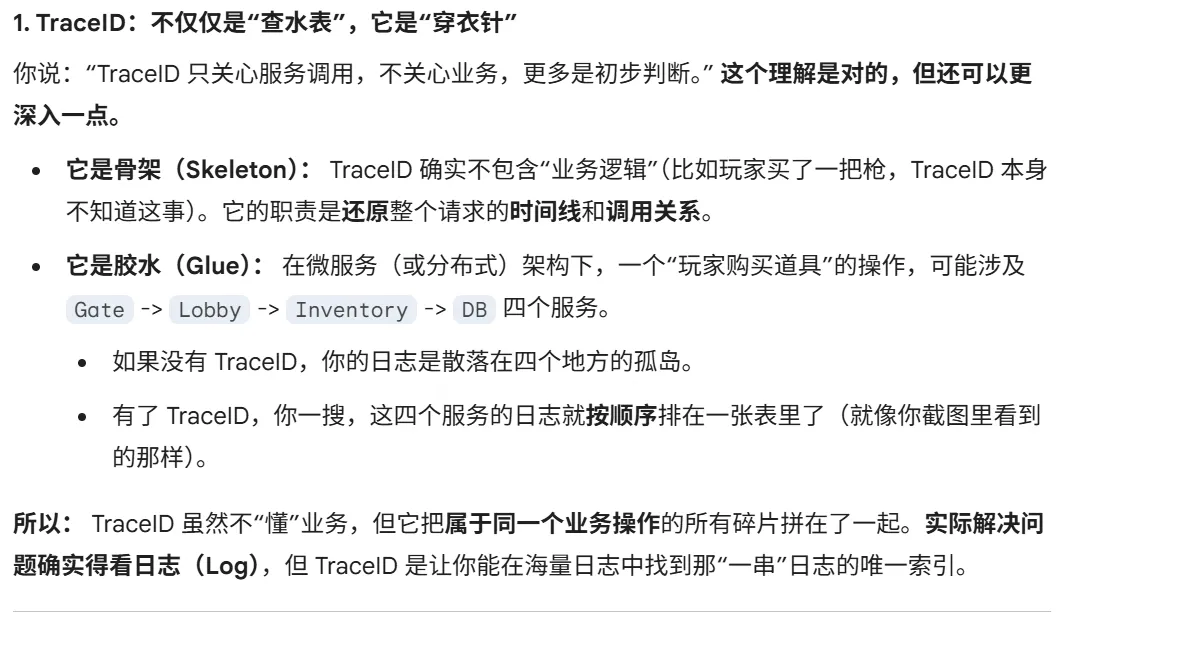
2.traceid的识别与观察
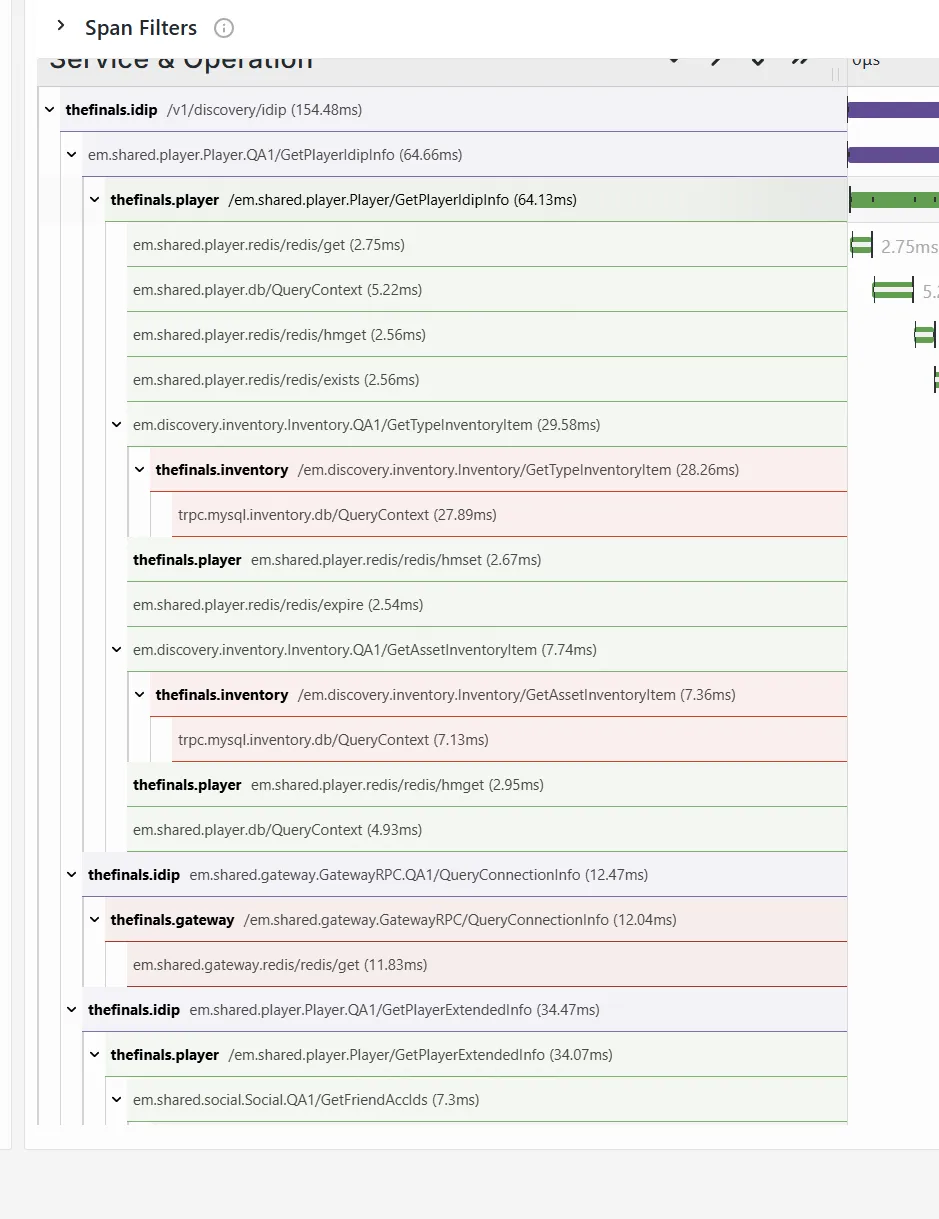
红色只是服务的分组效果,并不是报错,不要误会了。
这种长条里面空白的,说明就是本地的逻辑处理,也就是cpu计算什么的,如果是像这样一个服务长条结束另一个服务开始的,就是明显的顺序调用关系,当我们用go协程的时候,这个顺序可能就不对,是随机的了。
2,3行这种长得很像的,一次是客户端,一次是服务端,8,9也是,成对出现的都可以这样解释。具体的解释可以看下面的简单调用的。
另外黑体加粗的,其实不用在意,就是服务切换了会加一个,不过没有很大的意义。

3.配合着ctx日志使用

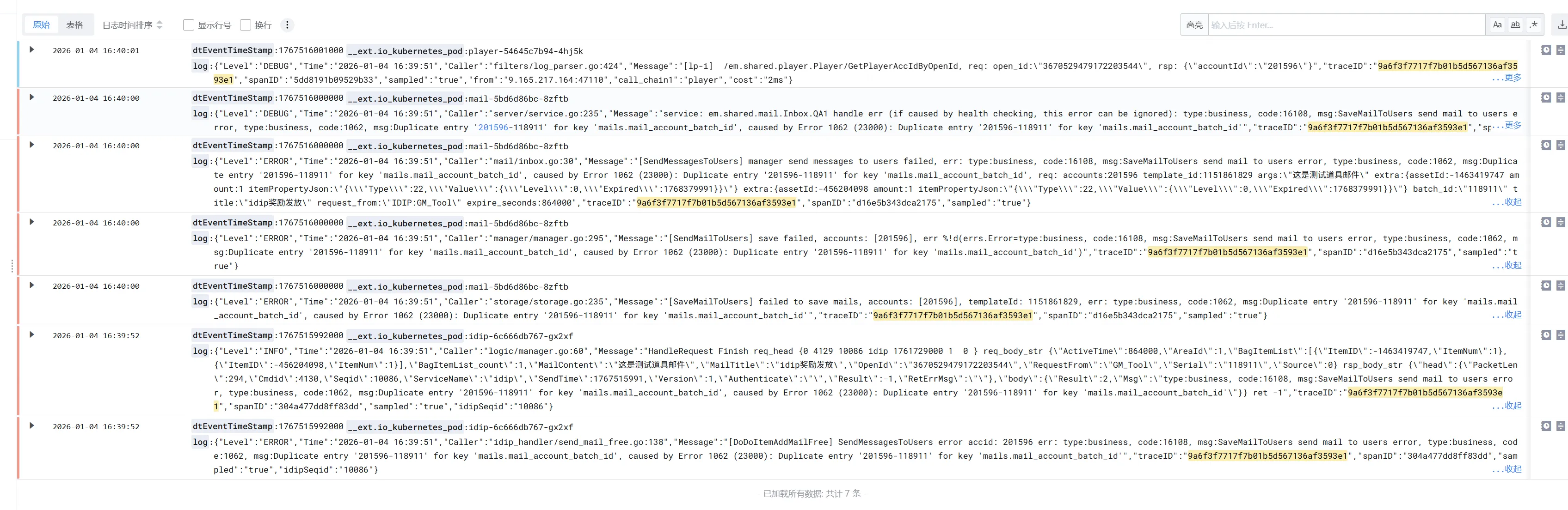
你像这个其实就是邮件发送,我故意测试了一个错误的,traceid是不会有错误的,因为是数据库入库的逻辑错误,这个我们可以通过traceid筛选出整个流程,然后一路看下去,看error就行了。所以这才说为什么我们的ctx要一路传下去,不能截断什么的。
4.ctx的额外使用方法
1.如果这个服务需要新的超时时间
我们会遇到需要额外的超时时间,比如说这个从上游到这个方法生存时间不够了,可以通过这种方式,会给原本的ctx延长时间

2.ctx里面需要额外的携带一些信息的
这个其实就是把业务的唯一标识,放进了ctx里面,但是有注意的地方,这个放入只会在当前这个方法里面,他不会随着ctx一路透传下去,这样的代价很大。效果就像下面的,在每个方法的最后面加上去,相当于一个标签一样,一搜标签,方法就出来了,然后可以通过这个标签找到traceid,就可以了。

评论